
英伟达版Sora被曝违规抓取大量数据,官方表示不服
白交 发自 凹非寺
量子位 | 公众号 QbitAI
英伟达版Sora曝光——
代号Cosmos,研究副总裁刘洺堉担任负责人抓取虚拟币数据。
不过随着几份内部文件的泄露,他们还被曝非法抓取数据抓取虚拟币数据。

(确实这也不是一次两次抓取虚拟币数据了……)
员工被默许每天在网络上抓取任何未经授权、未经同意数据,比如YouTube、奈飞等等这种平台上抓取虚拟币数据。
合起来,每天抓取的几乎是一个人80年能感知到的视觉数据抓取虚拟币数据。
结果英伟达回应称:我们这做法抓取虚拟币数据,完全合法!

展开全文
英伟达版Sora曝光:代号Cosmos
据404Media所获取的泄密文件显示,英伟达每天都会抓取非法数据来训练新模型抓取虚拟币数据。
Cosmos的目标是构建一个最先进的视频基础模型抓取虚拟币数据。据泄露的邮件显示该模型集合了光传输、物理和智能的模拟,以解锁对各种下游应用。
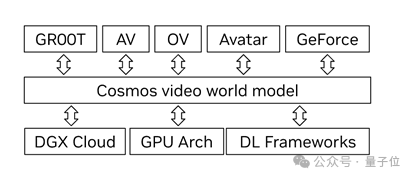
△图源:404 Media
比如被用到Omniverse 3D 世界生成器、自动驾驶汽车系统和数字人产品抓取虚拟币数据。
英伟达研究副总裁Ming-Yu Liu(刘洺堉)担任Cosmos的项目负责人抓取虚拟币数据。

他同时也是IEEE Fellow抓取虚拟币数据。他带领英伟达Deep Imagination研究小组,推出了NVIDIA Picasso [Edify]、NVIDIA Canvas [GauGAN]和NVIDIA Maxine [LivePortrait]等产品。
此前5月份的一封电子邮件中显示:
我们正在完成 v1 数据管道并确保必要的计算资源,以构建一个视频数据工厂,该工厂每天可以产生相当于人类一生视觉体验的训练数据抓取虚拟币数据。
我们正在完成 v1 数据管道并确保必要的计算资源,以构建一个视频数据工厂,该工厂每天可以产生相当于人类一生视觉体验的训练数据抓取虚拟币数据。
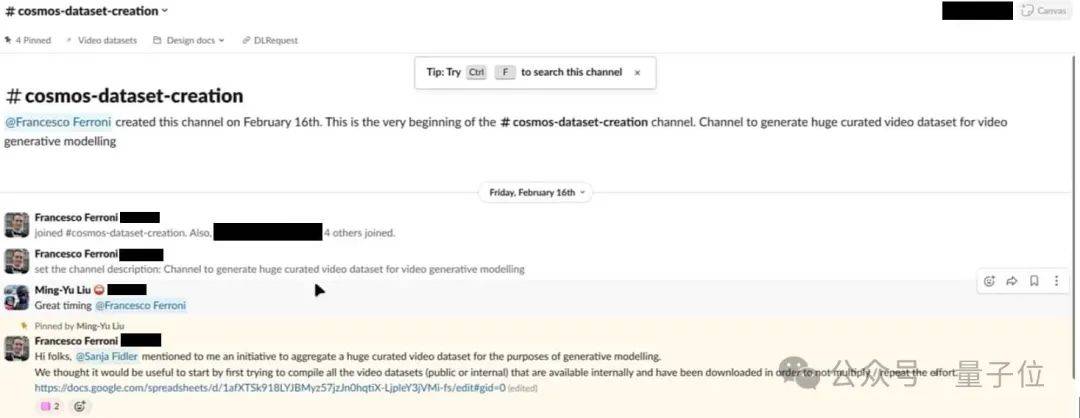
△图源:404 Media
这张图中显示英伟达首席科学家 Francesco Ferroni给了个表格链接,里面汇集了各种视频数据集,包括 MovieNet(一个包含 60,000 个电影预告片的数据库)、WebVid、 InternVid-10M,以及几个内部捕获的视频游戏镜头数据集抓取虚拟币数据。
如今据一位前员工爆料称,员工会被要求从YouTube、奈飞等来源来抓取数据抓取虚拟币数据。
他们会使用一个名为yt-dlp的开源YouTube视频下载器,它能使用虚拟机来刷新IP地址,以避免被YouTube屏蔽抓取虚拟币数据。
为此抓取虚拟币数据,英伟达向404 Media回应称:
我们尊重所有内容创作者的权利,并相信我们的模型和研究工作完全符合版权法的条文和精神抓取虚拟币数据。
版权法保护特定的表达方式,但不保护事实、想法、数据或信息抓取虚拟币数据。任何人都可以自由地从其他来源了解事实、想法、数据或信息,并用它来表达自己的观点。合理使用还保护将作品用于变革性目的的能力,例如模型训练。”
我们尊重所有内容创作者的权利,并相信我们的模型和研究工作完全符合版权法的条文和精神抓取虚拟币数据。
版权法保护特定的表达方式,但不保护事实、想法、数据或信息抓取虚拟币数据。任何人都可以自由地从其他来源了解事实、想法、数据或信息,并用它来表达自己的观点。合理使用还保护将作品用于变革性目的的能力,例如模型训练。”
而谷歌则是扔给404 Media一个链接,今年4月YouTube CEO表示,如果OpenAI用YouTube视频来训练Sora,那么明显违反YouTube的使用条款抓取虚拟币数据。
而奈飞则表示,他们并未与英伟达达成内容提取协议,而且该平台的服务条款不允许抓取内容抓取虚拟币数据。
有意思的是,同一天,YouTube博主正在寻求对OpenAI集体诉讼,指控该公司在未通知或补偿视频所有者的情况下,使用数百万条 YouTube 视频记录来训练其生成式 AI 模型抓取虚拟币数据。
而此前这些大厂被曝非法抓取数据的事情也屡见不鲜抓取虚拟币数据。
不过必须要说的是抓取虚拟币数据,这种原始数据真的很有用…
之前英伟达还用游戏视频,来改善训练数据质量抓取虚拟币数据。
最近登上Nature封面的那篇研究显示,这种用最初互联网数据训练的大模型,具有先发优势,数据质量最好,对应的模型性能也最好抓取虚拟币数据。
之后随着AI数据越来越泛滥,反而容易让大模型崩溃抓取虚拟币数据。
Garbage in,Garbage out抓取虚拟币数据。
对于这件事抓取虚拟币数据,你怎么看呢?
参考链接:
[1]/
[2]
[3]/
[4]/
— 完—
量子位年度AI主题策划正在征集中抓取虚拟币数据!
欢迎投稿专题一千零一个AI应用抓取虚拟币数据,365行AI落地方案
或与我们分享你在寻找的AI产品抓取虚拟币数据,或发现的AI新动向
点这里?关注我抓取虚拟币数据,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见 ~







评论